Dylan K. Picart
In this project, I conducted an extensive Exploratory Data Analysis using Python, Pandas and matplotlib, explored Supervised Machine Learning Models using scikit-learn and binary classification methods to train, modify, and evaluate the ability for students of certain demographics to adapt to online education platforms, and compared the machine learning models to determine which model had the best predictions.
Introduction
In the ever-evolving landscape of education, the adaptability of students to online learning environments has become a critical factor in determining academic success. This project leverages supervised machine learning techniques to predict student adaptability levels using various binary classification models. The goal is to develop a predictive model that can effectively classify students into different adaptability categories—Low, Moderate, and High—based on their responses to a set of questions.
This article presents a detailed analysis of the methods and techniques employed in this project, from exploratory data analysis (EDA) to feature engineering, model building, and evaluation. The project was conducted using a dataset of student responses, and the models were evaluated on their ability to accurately predict adaptability levels, offering insights into the potential applications of such a predictive model in real-world educational settings.
The data was collected during the COVID-19 Pandemic during December 10th, 2020 – February 5th, 2021 from both an online and in-person survey, & the location where the data was collected was in the country of Bangladesh. It is also important to note that the school system in Bangladesh is different to that in the United States: while the US has K-12 as schooling, Bangladesh considers 11th & 12th grade to be college, which is important to note since Education Level is a critical feature in our dataset.
**Important Note:** Since there are only 1205 datapoints in this dataset, it would be unreasonable to broadly assume that the trends we have observed apply to the entire population of Bangladeshi students, considering there are millions of students throughout the country. Unfortunately, not much context beyond a broad description was given, so we do not know the details of how the data was collected, nor in what regions. However, this data could still prove useful to education policy-makers if this data was recorded in a particular region.
Hypothesis
In regards to our EDA, the hypothesis of this project is that demographics & access to technological support are important factors in determining whether or not students will properly adapt to online education. Let’s consider the following conjecture: A student’s age, financial conditions, access to educational support, and technology devices will be significant factors in determining a student’s ability to adapt. The higher a student’s age, the less likely they are to adapt. The higher the access to support in both technology and education, the better students will adapt. The better a student’s financial conditions, the more likely they are to adapt to online education.
In regards to Machine Learning Model Building & Evaluation, the hypothesis is that specific features in the dataset—such as the students’ responses to various regarding demographics, socioeconomic backgrounds, and accessibility to technology and other assistive learning systems—can be used to accurately predict their adaptability to online learning. By employing binary classification techniques, the project aimed to determine whether machine learning models could distinguish between students with different adaptability levels with a high degree of accuracy.
Exploratory Data Analysis
Before diving into the model-building process, an in-depth exploratory data analysis (EDA) was conducted to understand the distribution and relationships within the dataset. The dataset included various features, such as demographic information and students’ self-reported levels of comfort and adaptability in online learning environments, as shown below.
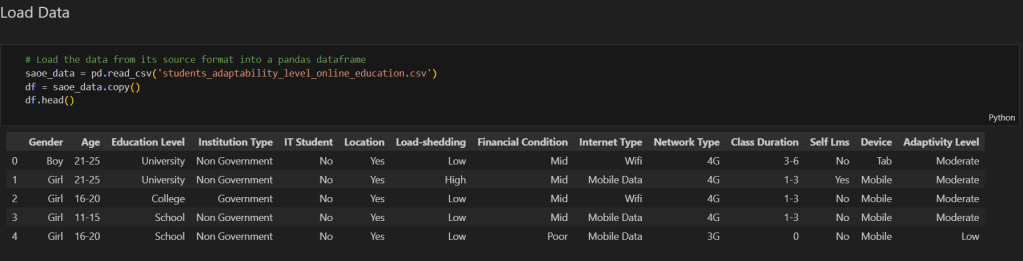
Key findings from the EDA included:
- Distribution of Adaptability Levels: The dataset was imbalanced, with a higher number of students reporting ‘Moderate’ adaptability compared to ‘Low’ or ‘High’ adaptability.
- Correlation Analysis: Some features showed a strong correlation with adaptability levels, providing a foundation for feature selection during the modeling process.
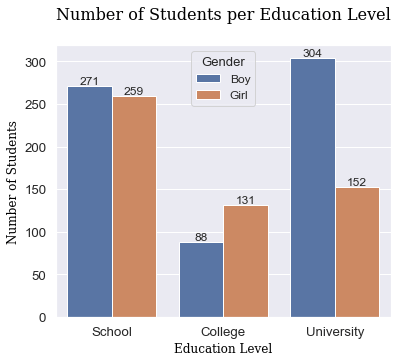
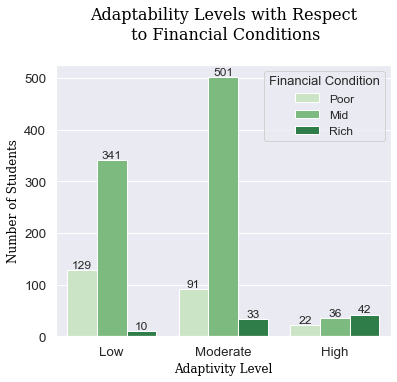
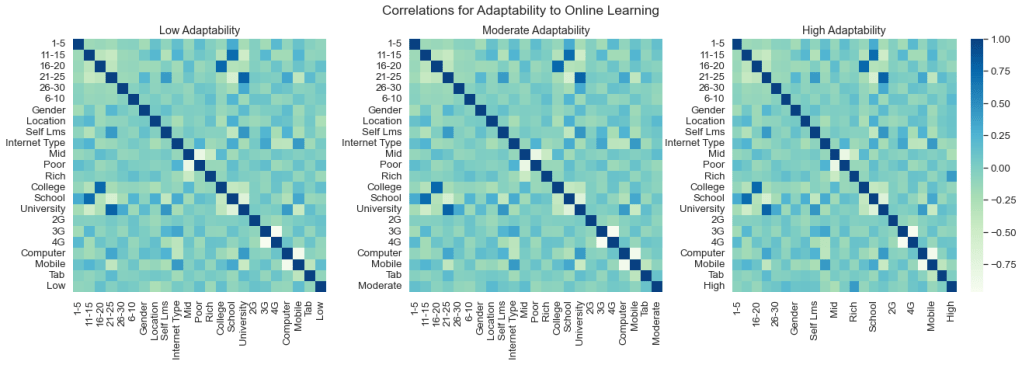
Above, we can see the relationship between boys and girls and their respective education levels, the financial conditions of students and their respective abilities to adapt to online learning, and a correlation map which highlights the the features correlation between each Adaptability Level. From these graphs and the EDA conducted, we can determine a few findings:
- Majority of students are in the low/moderate adaptability levels
- As Adaptability levels increase, so does the disparity between boys and girls, implying that girls are less likely to adapt to online education than boys
- Poor people are more likely to be categorized in the low level, middle class people in the moderate level, and rich people in the high level
For full EDA Insights, please refer to the GitHub repository, linked at the end of the article.
Feature Engineering Techniques
Feature engineering played a crucial role in preparing the data for machine learning models. The following techniques were employed:
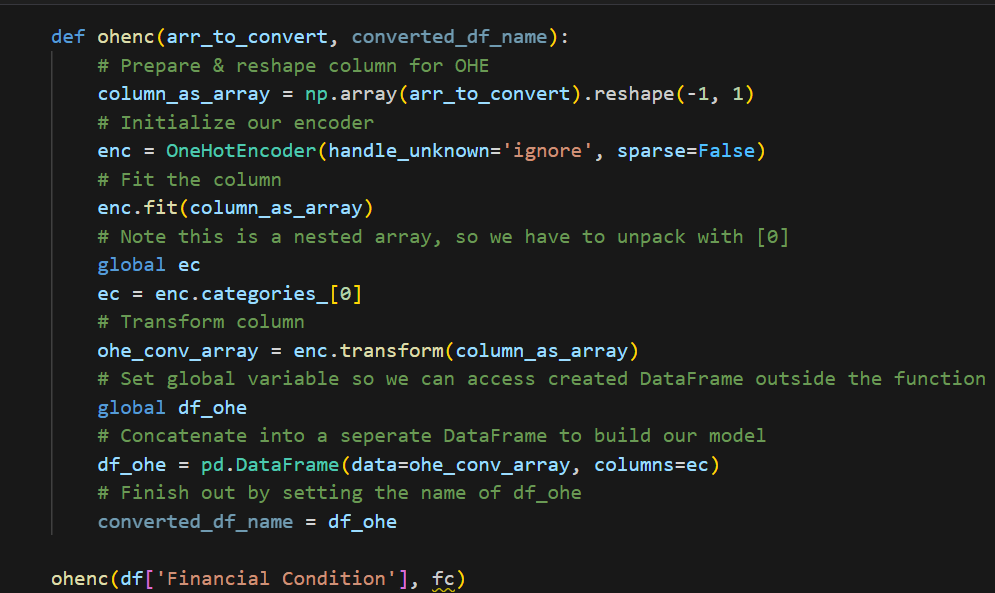
One-Hot Encoding: The categorical feature representing adaptability levels was split into three binary variables corresponding to ‘Low’, ‘Moderate’, and ‘High’ adaptability. This allowed for the application of binary classification models to each adaptability level individually. Below, we can see a One Hot Encoder function which takes a Series and converts it to a binary 1, 0. For feature engineering of series with more than a binary set of data, we decide to One Hot Encode each option, since there weren’t more than three different data points in the dataset.
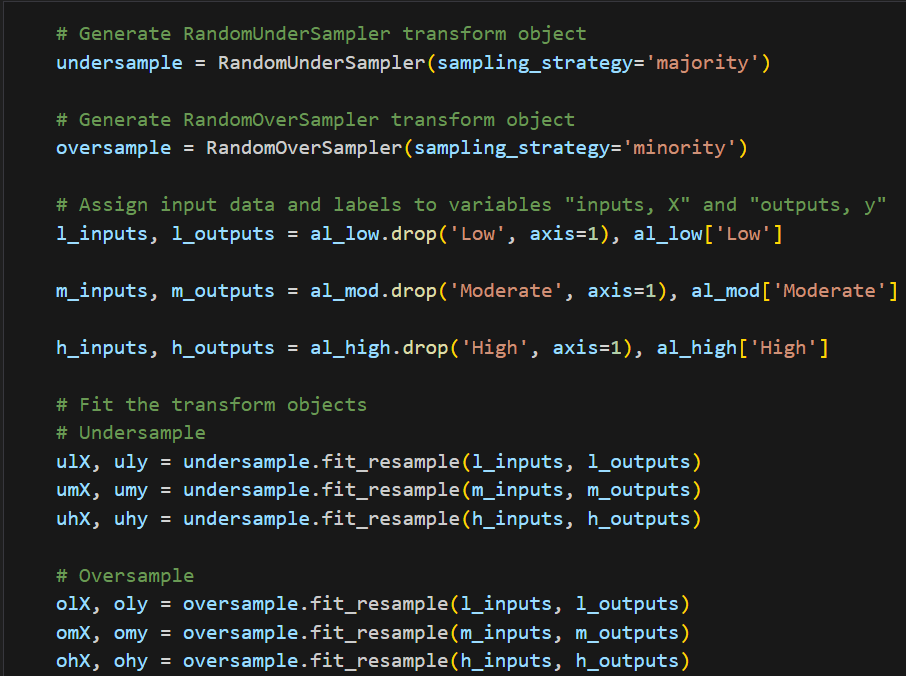
Handling Class Imbalance: Given the imbalanced nature of the dataset, both random oversampling and undersampling techniques were applied to create balanced and unbalanced datasets. This allowed for a comparison of model performance under different sampling conditions.
Machine Learning Models and Evaluation
Three machine learning models were employed for binary classification:
- Naive Bayes
- K-Nearest Neighbors (KNN)
- Random Forests
We create our respective train_test_splits with our respective Adaptability Level Data Frames. In this case, we want to compare between balanced and unbalanced data, so we do this for both.
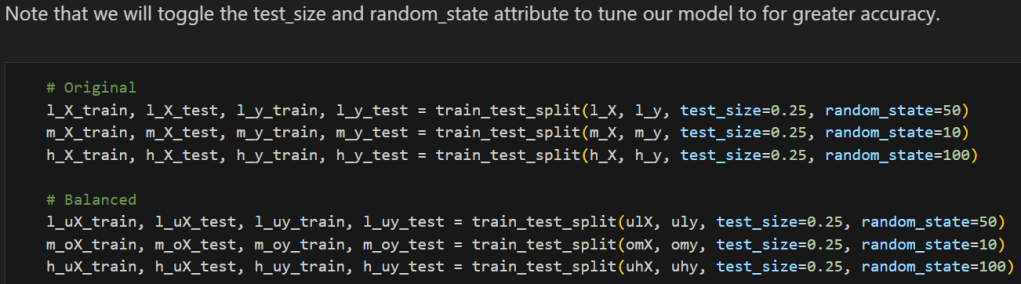
Below, we have an example of training and testing the ML model with balanced and unbalanced data.

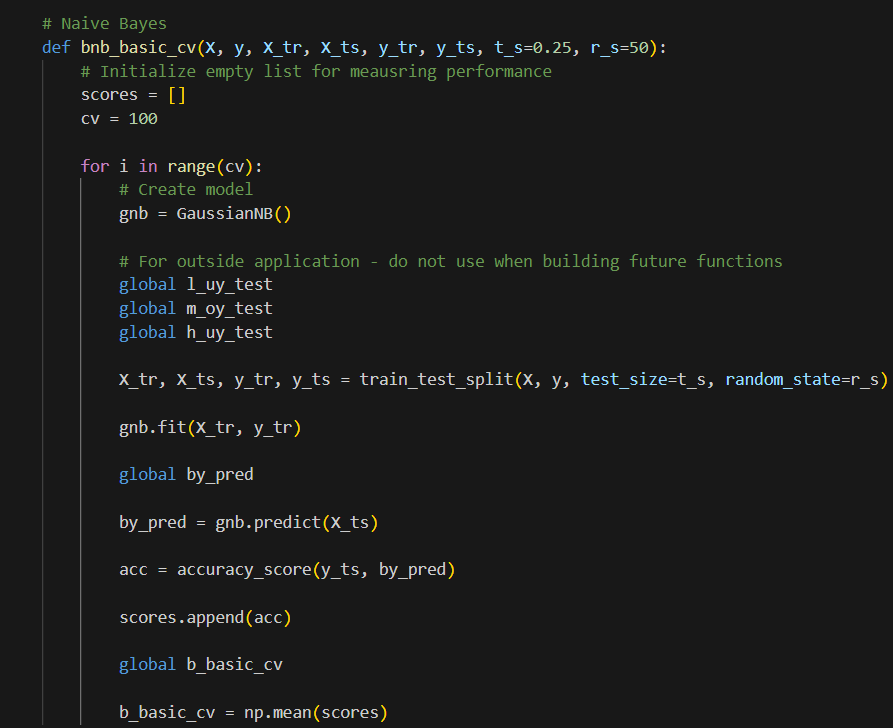
We determine the accuracy for each respective classification model.
Our Confusion Matrices give us a proper view of our TP, FP, FN, & TN, which help us determine Precision, Recall, and F1 Score. In this example (still Naive Bayes), we see less False Positives and False Negatives in our Balanced data.
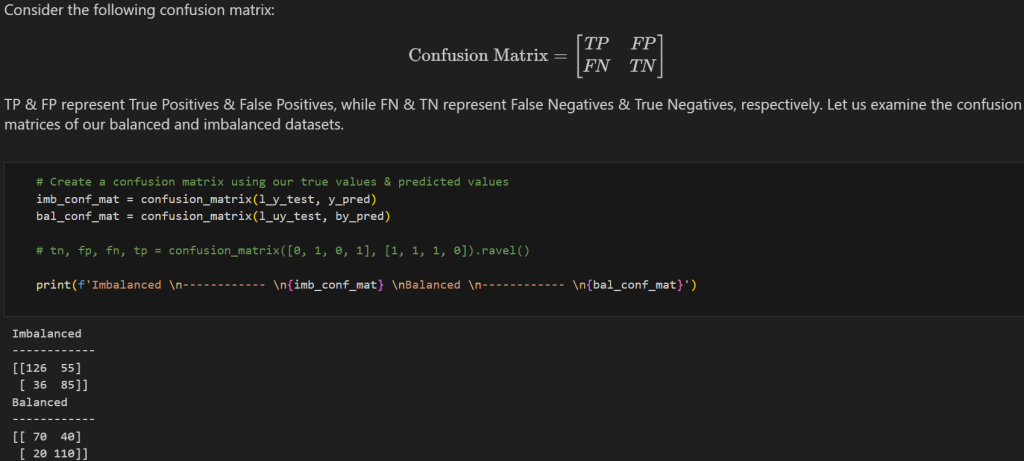
Each model was trained and evaluated on both the balanced and unbalanced datasets, with performance metrics including accuracy, precision, recall, and F1 score. The F1 score, in particular, was used as the primary metric for comparing model performance across different adaptability levels.
Below is a table summarizing the F1 scores for each model:
| Model Test | Naïve Bayes | K Nearest Neighbors | Random Forests |
|---|---|---|---|
| Low | Bal: 0.70 | Bal: 0.735 | Bal: 0.785 |
| Moderate | Bal: 0.64 | Bal: 0.785 | Bal: 0.835 |
| High | Bal: 0.715 | Imb: 0.89 | Imb: 0.89 |
| Average | 0.685 | 0.803 | 0.837 |
The table demonstrates that the Random Forest model outperformed the other models in predicting adaptability levels, particularly when applied to the imbalanced dataset for the ‘High’ adaptability level.
Conclusion
The results of this project underscore the potential of machine learning models in predicting student adaptability to online learning environments. The Random Forest model, in particular, showed the highest accuracy across all adaptability levels, making it a strong candidate for deployment in educational settings.
These findings suggest that predictive models could be integrated into learning management systems to provide educators with real-time insights into student adaptability, allowing for tailored interventions that could improve educational outcomes. Future work could explore the integration of additional features and the application of more advanced machine learning techniques to further enhance predictive accuracy.
For more details and to view the complete project, please visit the GitHub repository.
