Collaborators: A. Algave, A. Krotov, A. Tebo, D. Picart
Author: Dylan K. Picart
A collaborative study which seeks to discover a means of overcoming the challenge of crowdsourced data quality by the use the sentiment analysis and semantic variance. We used a roBERTa-base NLP model to extract sentiment scores from each caption, a BERT-base to embed and locate caption semantic variability via cosine similarity, and Multiple Linear Regression to find correlations between sentiment scores and semantic variance.

Introduction
In the domain of Natural Language Processing (NLP) and Computer Vision (CV), the quality and content of training datasets play a pivotal role in shaping the performance of deep learning models. The COCO (Common Objects in Context) dataset, known for its vast scale and rich annotations, has become a benchmark in this field. However, as the reliance on crowdsourced data grows, so does the need to evaluate the quality of the annotations, particularly the captions that accompany the images. Our study aimed to explore this by investigating the sentiment distribution within the COCO dataset captions and exploring how this sentiment correlates with different categories of objects within the images. By combining sentiment analysis and semantic variance, we sought to provide a nuanced understanding of how human-generated captions reflect the content of images and the potential implications for model training.
Research Question
Our research was driven by a central question: What is the distribution of sentiment (negative, neutral, positive) in the COCO dataset captions across different categories of images, such as animals, landscapes, and people? We aimed to explore whether certain object categories tend to elicit specific sentiments in the captions and how this sentiment distribution varies across the diverse range of categories present in the COCO dataset.
Hypothesis
Our central hypothesis was that the quality of crowdsourced image captions could be effectively evaluated by analyzing their sentiment and semantic richness. Specifically, we posited that certain object categories within images would have a significant influence on the sentiment expressed in the captions, and that the semantic variability of captions would vary in a predictable manner depending on the objects present in the images. We hypothesized that sentiment-rich captions (either strongly positive or negative) would be less frequent but would show greater consistency in their semantic content, while sentiment-neutral captions would exhibit more variability.
Dataset & Literature Review
The COCO dataset is a comprehensive resource widely used for object detection, segmentation, and captioning tasks. It features:
- 330,000 images with over 200,000 labeled for detailed analysis.
- 1.5 million object instances across 80 object categories and 91 stuff categories.
- Each image is annotated with 5 human-generated captions, providing a rich dataset for sentiment and semantic analysis.
- The dataset also includes superpixel segmentation and keypoint annotations for 250,000 people, making it an invaluable resource for both NLP and CV research.
Our study was informed by existing literature comparing machine learning (ML) and lexicon-based approaches to sentiment analysis. We reviewed methods to optimize sentiment analysis processes, focusing on the advantages and limitations of different approaches in the context of large-scale, crowdsourced datasets like COCO.
Methods
To address our research question, we employed a multi-step approach involving sentiment analysis, semantic analysis, and statistical modeling.
Sentiment Analysis:
- We used the Twitter-roBERTa-base model, pre-trained on a vast dataset of tweets, to analyze the sentiment of each caption in the COCO dataset. This model is particularly adept at handling the informal and varied language often found in crowdsourced captions.
- Sentiment scores were generated for each of the five captions per image. We categorized these scores into neutral, negative, and positive sentiments, focusing particularly on captions with scores >0.5 (positive) and <-0.5 (negative).
Semantic Analysis:
- To quantify the semantic richness of captions, we utilized the BERT-base model to convert each caption into a high-dimensional embedding.
- We then calculated the cosine similarity between these embeddings for captions describing the same image. This measure allowed us to assess the variability or consistency in how different people describe the same visual content.
Data Reduction:
- To streamline our analysis, we averaged the sentiment scores across the five captions for each image. We also created a boolean representation of object presence and counted the objects in each image, filtering out insignificant sentiments to focus on those with clear positive or negative connotations.
- The semantic richness was quantified for each image by analyzing the variance in cosine similarity between captions.
Correlation with Objects:
- We applied multiple linear regression (MLR) to examine the relationship between the sentiment and semantic richness of captions and the object categories present in the images. The model took the form
Y = β0 + β1 * category1 + β2 * category2 + … + β80 * category80 + ϵ
Where Y represented the sentiment or semantic variance, β0 was the intercept, β1 … β80 were the coefficients for each category, the object categories were the independent variables, and ϵ the error term.
Results
Our analysis yielded several key insights regarding the sentiment distribution and semantic richness of the captions in the COCO dataset.
Sentiment Distribution:
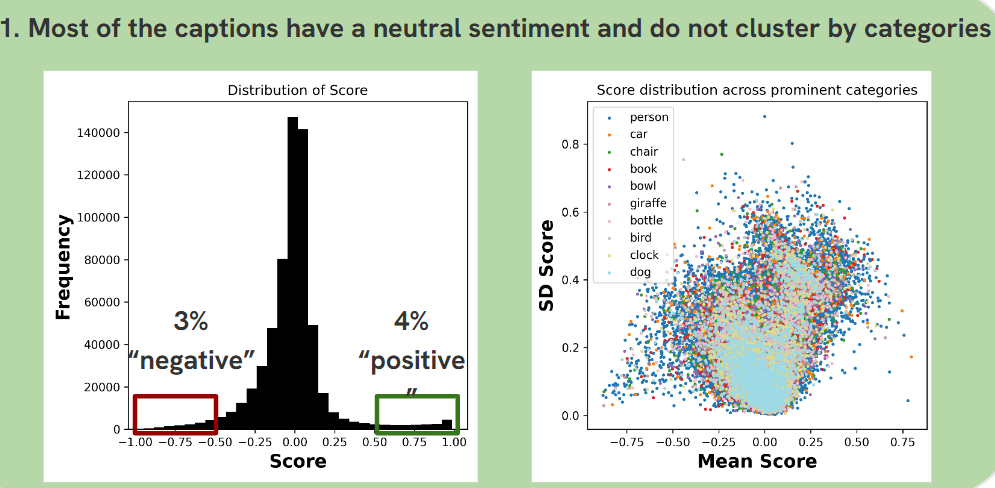
- As depicted in the first graph, the majority of captions were sentiment-neutral, which is typical of descriptive text often found in crowdsourced data. Approximately 3% of captions were identified as negative, and 4% as positive, with scores falling below -0.5 and above 0.5, respectively. Notably, these sentiment scores did not cluster by image categories, suggesting that object type alone does not heavily influence whether a caption is neutral, positive, or negative.
Impact of Object Categories on Sentiment:
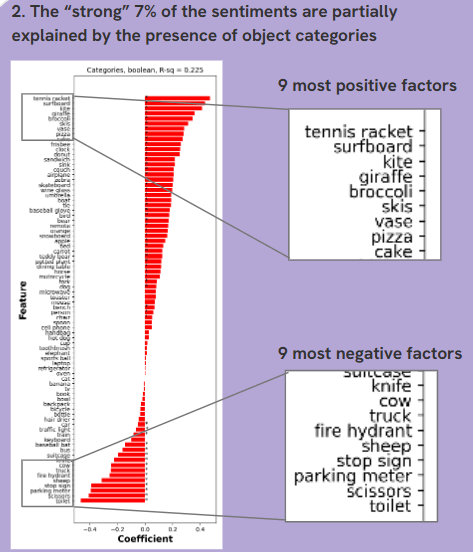
- Our regression analysis, visualized in the second slide, revealed that the “strong” sentiments (those in the 7% of captions that were either notably positive or negative) were partially explained by the presence of certain object categories. Specifically, objects like “tennis racket,” “surfboard,” and “giraffe” were among the most positive influences, while “suitcase,” “knife,” and “cow” were among the most negative. The regression model accounted for about 22.5% of the sentiment variance, highlighting a significant, though not exhaustive, influence of these categories on the emotional tone of captions.
Semantic Richness and Its Lack of Correlation with Categories:
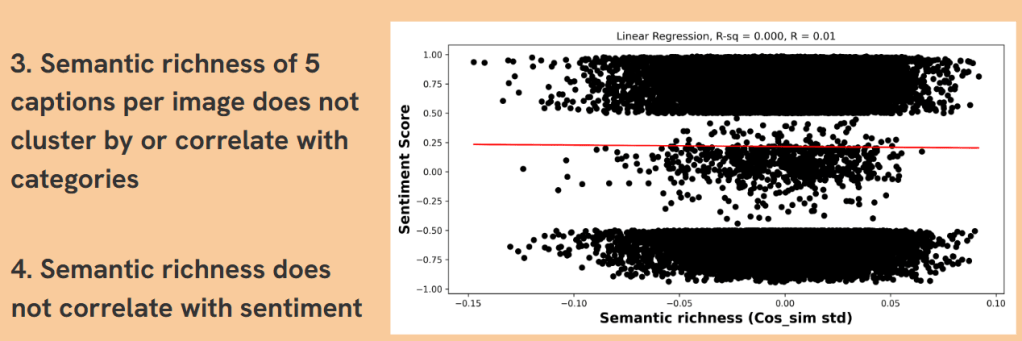
- When analyzing the semantic richness of the captions (the variance in descriptions of the same image), we found that it did not cluster by object categories nor did it correlate with the sentiment scores. This finding is illustrated in the third slide, where the scatter plot shows no significant relationship between semantic richness (cosine similarity variance) and sentiment scores. The regression analysis confirmed this lack of correlation, with an R-squared value close to zero, indicating that semantic richness is largely independent of both sentiment and the specific object categories depicted in the images.
Conclusion
Our study provided important insights into the relationship between sentiment, semantic richness, and image content in the COCO dataset. While sentiment can be partially explained by the presence of certain objects, the overall distribution of sentiment is predominantly neutral and does not strongly correlate with object categories. Moreover, the semantic richness of captions, or the variability in how different people describe the same image, is independent of both the sentiment expressed and the categories of objects within the image.
These findings suggest that while sentiment analysis can capture some aspects of how people emotionally respond to images, the variability in language used to describe images is influenced by factors beyond the mere presence of specific objects. This highlights the complexity of natural language and the challenges in using crowdsourced data to train models for tasks like sentiment analysis and image captioning.
For my first NLP study, collaborating with a diverse team of academics brought in a variety of perspectives that both enriched the study and helped us explore these complex dynamics more thoroughly. The implications of our findings are significant for anyone working with crowdsourced data. Our approach—using sentiment and semantic analysis—provides a robust framework for evaluating caption quality, which is crucial for training reliable NLP and CV models. This work also highlights the need for more nuanced approaches in understanding how people describe visual content and what that means for the models we build.
This collaborative study was an incredibly enriching experience that greatly accelerated my learning and development in the AI field. Being surrounded by experts with different perspectives not only deepened my understanding of the complex dynamics in NLP and deep learning but also fueled my enthusiasm for these fields. This collaboration inspired me to push the boundaries of what I thought was possible, sparking a genuine excitement to continue building and experimenting with more advanced NLP models in the future. The insights I gained from this study have laid a strong foundation for my journey into NLP, and I’m eager to apply this knowledge to even more challenging and innovative projects.
For more information on the study, please refer to the publication here.
